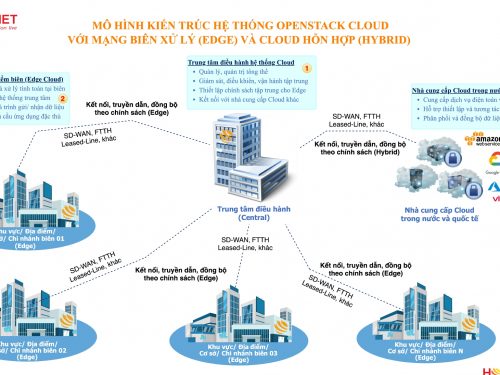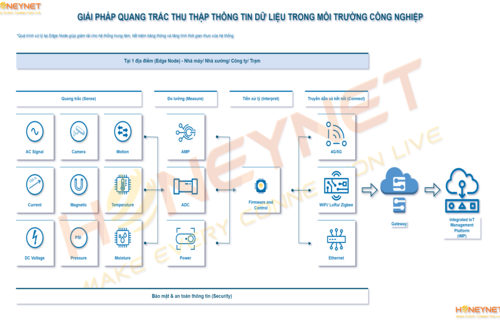
Kiến trúc Microservices là một chủ đề phổ biến trong những năm gần đây và đã từng có rất nhiều hội thảo nói về cách triển khai, quản lý và thực hiện Microservices, nhưng gần đây xu hướng này có vẻ đã chậm lại. Thay vào đó, mọi người bắt đầu nói về mức độ phức tạp của Microservices. Do tính phức tạp cao của Microservices, mọi người không còn coi Microservices là thuốc chữa bách bệnh mà chỉ coi đó là một giải pháp khả thi.
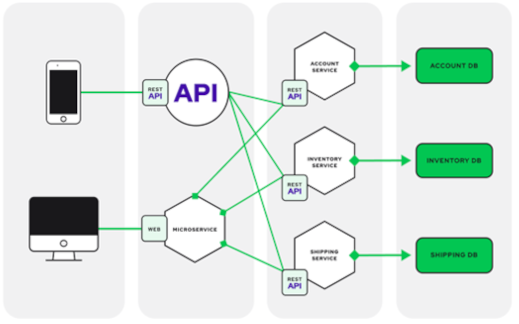
Hình 01: Minh họa kiến trúc Microservices
1. Microservices lý tưởng là gì?
Nhưng trước khi bắt đầu giới thiệu về Microservices, chúng ta hãy xem xét một Microservice lý tưởng nó sẽ được trông như thế nào?
Microservices lý tưởng phải có các đặc điểm sau:
- Không có mã được chia sẻ
- Không có dữ liệu được chia sẻ
- Có ranh giới ngữ cảnh độc lập trên các miền (hệ thống/ môđun) cụ thể
- Có thể được triển khai độc lập, riêng lẻ
- Nguyên tắc trách nhiệm đơn lẻ
Chúng ta có thể hình dung là nó trông giống như hình bên dưới, với một sơ đồ kiến trúc.
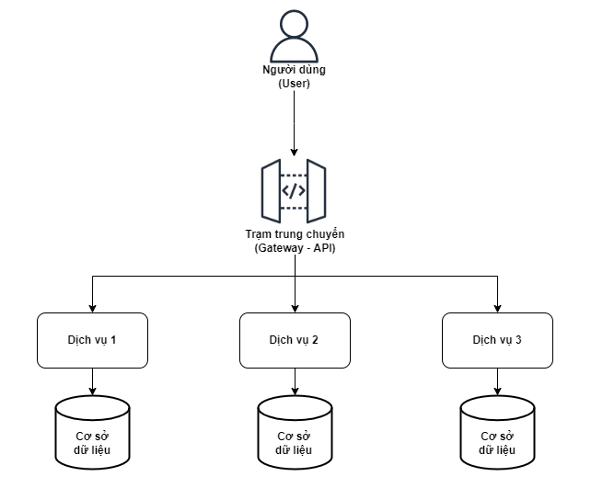
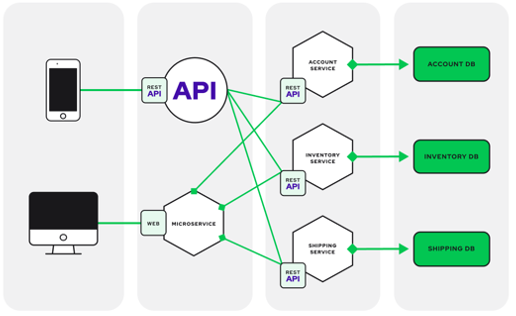
Hình 02: Kiến trúc Microservices lý tưởng
Khi người dùng (khách hàng) giao tiếp với hệ thống phụ trợ (trung chuyển – Gateway), chương trình này thường sẽ định tuyến yêu cầu đến một dịch vụ cụ thể thông qua cổng API theo một quy tắc nhất định và Microservices có thể xử lý yêu cầu một cách độc lập mà không liên quan đến thành phần khác.
2. Còn thế giới thực thì sao?
Thế giới thực thường không đẹp như chúng ta nghĩ. Một sản phẩm dùng ban đầu có thể là lý tưởng, nhưng nó sẽ thay đổi và khác nhiều khi có nhiều yêu cầu được thêm vào, thời gian đó chúng ta có thể sử dụng nén lại, và thậm chí chúng ta phải sửa các lỗi đã xảy ra. Rồi sản phẩm sẽ ngày càng được làm lại, chế tác một cách nguệch ngoạc.
Chúng ta cũng có thể biết được từ một hình vẽ nhìn rõ ràng nó là một toà nhà, cây cầu, mảnh vườn nếu ít nhất có một thiết kế và kế hoạch tốt ngay từ ban đầu, còn nếu không có bản thiết kế hay kế hoạch nào ngay từ đầu, chúng ta thậm chí không thể tưởng tượng. Cuối cùng người vẽ cũng không nhận ra là anh/ chị/ chúng ta sẽ trông nó như thế nào!?
Vì vậy, trong một sơ đồ kiến trúc, nó có thể sẽ giống như sau hình bên dưới, đây là thế giới thực.
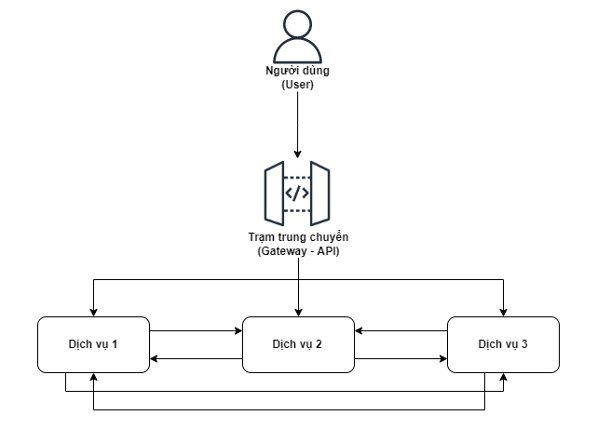
Hình 03: Kiến trúc nhập nhằng trong thế giới thực
A, B và C đều có trách nhiệm riêng của họ để xử lý các nhiệm vụ trong ranh giới của miền (hệ thống/ môđun), nhưng một khi nhu cầu tăng lên, A phát hiện ra rằng nó cần dữ liệu của B, B cần chức năng của C và thậm chí C phải gọi A lại. Cuối cùng, kiến trúc trở thành một quả bóng bùn nhùn rất lớn (mức độ vòng lặp xảy ra rất cao – loop)
Và nó có thể có nhiều lý do như sau:
- Thông thường, một tổ chức không có vai trò của kiến trúc sư. Vì vậy, không có cách nào để phát triển hệ thống đúng theo yêu cầu.
- Nếu không có kiến trúc sư, hệ thống không thể được xác định một cách chính xác và rõ ràng ngay từ đầu.
- Tập trung vào việc cung cấp chức năng một cách nhanh chóng và bỏ qua các yêu cầu phi chức năng về quản lý, quản trị.
- Thời gian hoàn vốn cho sản phẩm là rất ngắn. Vì vậy, chúng ta cũng chỉ có thể trả lời cho bất kỳ câu hỏi trực tuyến nào trong một khoảng thời gian ngắn.
- Mọi thứ diễn ra trên môi trường trực tuyến (Online) và những tính năng lại không được phép tắt (Off) cho đến khi nhu cầu kinh doanh bị loại bỏ.
Bây giờ chúng ta đã hiểu về thực tế của việc phát triển phần mềm, hãy cùng xem xét những vấn đề chúng ta gặp phải khi thiết kế Microservices. Điều đầu tiên cần hiểu là một hệ thống Microservices về bản chất là một kiến trúc phi tập trung cao cấp, vì vậy các lỗi ngụy biện gặp phải trong kiến trúc phi tập trung cũng sẽ xuất hiện trong Microservices.
3. Những lỗi thường gặp làm sụp đổ các hệ thống phi tập trung
- Môi trường Internet là đáng tin cậy
Mọi người luôn cho rằng mạng giữa hai điểm cuối là ổn định và đáng tin cậy. Nhưng thực tế là các gói tin trên mạng có thể bị mất, thậm chí kết nối có thể bị gián đoạn.
Do đó, một hệ thống phi tập trung phải có cơ chế thử lại để tối đa hóa độ tin cậy trước khi đưa vào thực tế.
- Không có mạng lag
Khi thiết kế một kiến trúc phi tập trung, tiềm thức thường có nhận thức rằng không có sự chậm trễ giữa hai điểm cuối, dẫn đến việc thiết kế một số chức năng được phân phối cho nhiều điểm cuối để thực thi.
Thật không may, độ trễ giữa các điểm cuối không bao giờ có thể bằng 0, ngay cả trên mạng nội bộ (LAN).
Do đó, điều quan trọng là phải đặt ngưỡng thời gian chờ khi thực hiện cuộc gọi từ xa, ngay cả khi cơ sở dữ liệu được kết nối. Ngoài ra, các cuộc gọi (Call Function/ Call API) là ngắn hạn và thường xuyên cũng nên được “đóng gói” thành một cuộc gọi càng nhiều càng tốt. Lấy Redis làm ví dụ, cần tận dụng tốt pipeline hoặc multi để giảm số lượng “chuyến đi” khứ hồi (RTT) giữa các điểm cuối.
- Băng thông không giới hạn
Mọi người luôn cảm thấy rằng không có giới hạn về băng thông mạng giữa các điểm cuối, vì vậy họ gửi dữ liệu một cách vô nguyên tắc.
Và trên thực tế, băng thông giữa các điểm cuối nhỏ hơn chúng ta nghĩ.
Đặc biệt, một số truy vấn cơ sở dữ liệu, chẳng hạn như MySQL/ MariaDB dùng SELECT *, có xu hướng làm cạn kiệt băng thông mà không biết. Khi nhu cầu phát triển, bảng dữ liệu cũng sẽ trở nên lớn hơn, và có thể có nhiều dữ liệu lớn như BLOB hoặc TEXT sẽ được ghi vào bảng. Lúc này, đảm bảo là SELECT * sẽ tiêu tốn nhiều băng thông hơn bạn nghĩ.
- Internet là an toàn
Đây là một cạm bẫy phổ biến, trên thực tế mọi người luôn nghĩ rằng mạng nội bộ là an toàn.
Nhưng hoàn toàn không phải vậy, đó là lý do tại sao “không tin tưởng” đã được ủng hộ rộng rãi trong những năm gần đây.
- Cấu trúc liên kết sẽ không thay đổi
Ngụy biện này thật buồn cười. Giả định rằng cấu trúc liên kết mạng không thay đổi, vì vậy hai điểm cuối luôn có thể tìm thấy nhau thông qua một IP hoặc FQDN (Fully Qualified Domain Name) được xác định trước.
Nhưng thực tế là các cấu trúc liên kết có thể thay đổi vì nhiều lý do khác nhau, bao gồm phân đoạn VPC (Virtual Private Cloud), di chuyển đám mây công cộng hoặc sự phát triển của hệ thống.
- Có quản trị viên hệ thống
Chúng tôi luôn mong đợi có ít nhất một quản trị viên hệ thống quản lý, quản trị dịch vụ.
Thông thường trong mọi tổ chức, sẽ có một vai trò vận hành để duy trì hệ thống. Do đó, bộ phận bảo trì và vận hành đóng vai trò là người quản lý hệ thống, khi có bất kỳ sự cố nào xảy ra, bộ phận vận hành và bảo trì có thể là người đầu tiên tìm ra.
Đây là “Sai Lầm Lớn”.
Bất kỳ hệ thống nào cũng phải có khả năng quan sát và các nhà phát triển hệ thống phải có khả năng phát hiện các vấn đề tiềm ẩn từ phép đo từ xa.
Có 04 chỉ số đo từ xa phổ biến:
- Ghi nhật ký: Hồ sơ thực thi do hệ thống để lại được sử dụng để theo dõi hành vi của hệ thống và trong một hệ thống phi tập trung, phải có khả năng theo dõi hành vi xuyên hệ thống.
- Tracing: được sử dụng để theo dõi chu kỳ thực hiện của nhiệm vụ, chẳng hạn như tổng thời gian đã dành để hoàn thành nhiệm vụ, … Các công cụ thường được sử dụng trong các hệ thống phi tập trung là các công cụ: Jaeger/ Open-tracing/ Khác.
- Chỉ số: Trạng thái có thể được đo lường trong quá trình thực thi hệ thống, chẳng hạn như số lần thực thi API, số lỗi, …
- Cấu hình: Mức tiêu thụ tài nguyên nền của hệ thống, chẳng hạn như CPU, RAM, …
- Không có chi phí truyền tải
Đây thực sự cũng là một “Sai Lầm Nghiêm Trọng”.
Chúng ta phải hiểu rằng bất kỳ cuộc gọi (call Function/ call API) từ xa nào cũng có phí, đặc biệt là trên đám mây công cộng (Public Cloud), và chi phí đó thậm chí còn đáng kể hơn. Ngay cả khi chỉ truy cập cơ sở dữ liệu hoặc thực hiện các yêu cầu HTTP/ HTTPs gửi đi cũng phải trả chi phí.
Vì vậy, dù cuộc gọi từ xa là gì thì nó cũng phải được tối ưu hóa, cho dù đó là số lượng cuộc gọi hay dung lượng của dữ liệu.
- Web là đồng nhất
Đây là một cái bẫy dễ bỏ qua.
Các mạng “chắc chắn không đồng nhất”, vì vậy khi một điểm cuối gọi (call Function/ call API) một điểm cuối khác, chúng ta không thể đảm bảo rằng các cuộc gọi sẽ theo thứ tự như mong đợi. Nói cách khác, không thể kỳ vọng đúng hoàn toàn về thứ tự của các cuộc gọi từ xa.
4. Kết luận
Sau những cuộc thảo luận này, chúng ta đều có thể đồng ý rằng các kiến trúc phi tập trung thực sự là phức tạp.
Microservices là kiến trúc phân tán quy mô lớn, nó bao gồm vô số điểm cuối, thiết kế của mỗi điểm cuối phải tính đến các yếu tố khác nhau vừa được đề cập bên trên. Hơn nữa, Microservices cũng có những vấn đề riêng phải đối mặt, chẳng hạn như tính nhất quán của dữ liệu, khả năng mở rộng hệ thống, …
Do đó, trong các loạt bài tiếp theo, chúng tôi sẽ nói về chủ đề độc quyền của Microservices.
Nguồn: HONEYNET và Internet